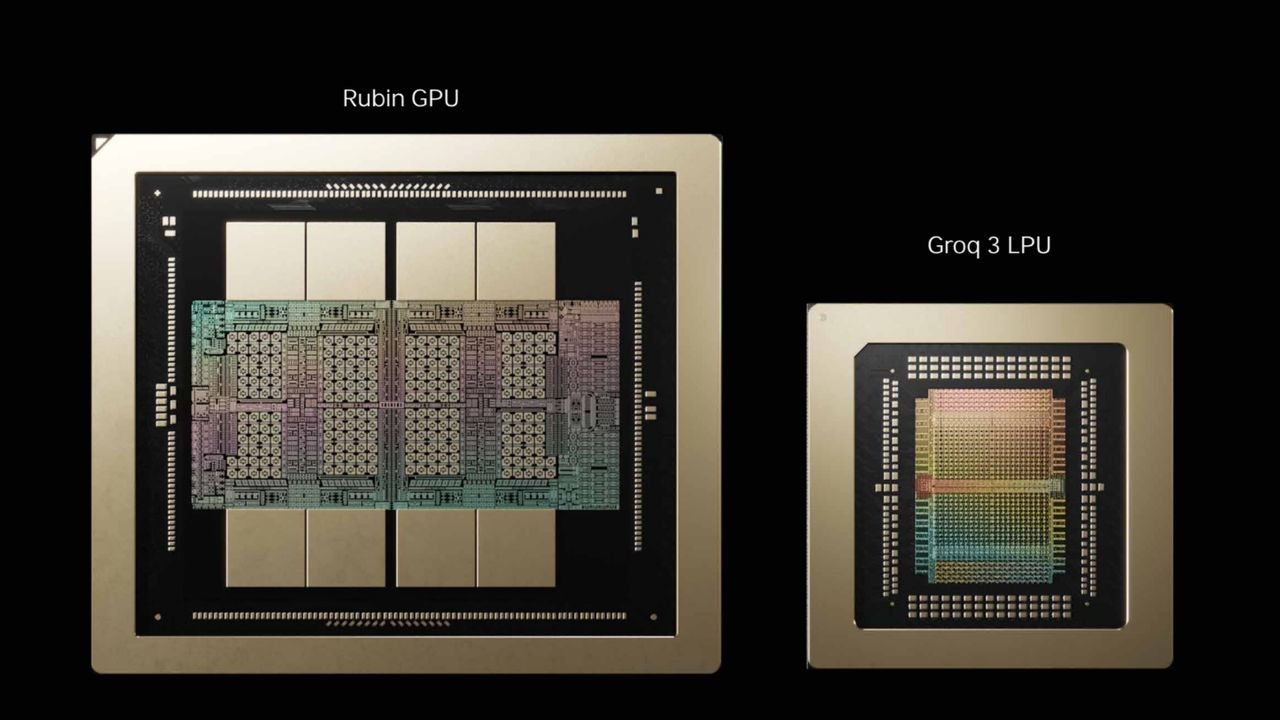
A Nvidia lançou o Groq 3 LPU na GTC 2026, o primeiro chip do seu acordo de US$20 bilhões com a startup Groq. Este acelerador de inferência baseado em SRAM atua como um coprocessador de decodificação na plataforma Vera Rubin e será fabricado pela Samsung em processo de 4nm, com lançamento previsto para o 3º trimestre de 2026. É o primeiro produto da Nvidia em escala de rack construído com silício não-GPU, já substituindo um chip próprio da empresa no roteiro.
O chip LP30, coração do rack Groq 3 LPX, possui 512 MB de SRAM on-chip por die, entregando 150 TB/s de largura de banda de memória — um valor que supera os 22 TB/s das HBM4 em cada GPU Rubin. Um rack LPX completo abriga 256 LPUs, totalizando 128GB de SRAM e 40 PB/s de largura de banda agregada. A Nvidia afirma que o rack LPX, quando emparelhado com um Vera Rubin NVL72, oferece 35 vezes mais throughput por megawatt para modelos de trilhões de parâmetros, com um preço-alvo de US$45 por milhão de tokens.
As GPUs Rubin lidam com a fase de pré-preenchimento, processando contextos de entrada longos, enquanto os LPUs Groq assumem a fase de decodificação, gerando tokens de saída com baixa latência. A plataforma de orquestração Dynamo da Nvidia gerencia a divisão de trabalho entre o hardware heterogêneo.
O design original do Groq LPU usava uma arquitetura VLIW e grandes pools de SRAM on-chip, proporcionando latência determinística e altas taxas de token. No entanto, sua capacidade era limitada (230MB de SRAM). O Groq LP30 endereça essas limitações com 512 MB de SRAM por die e 1.23 FP8 PFLOPS de capacidade de computação. A Samsung aumentou a produção e a AWS anunciou que implementará LPUs Groq 3 juntamente com mais de um milhão de GPUs Nvidia.
O Rubin CPX, um acelerador de inferência baseado em GDDR7 anunciado anteriormente, esteve notavelmente ausente na GTC. Parece que o CPX foi removido do roteiro da Nvidia, sendo substituído na hierarquia da plataforma pelo Groq 3 LPX. O LPU Groq oferece maior largura de banda sem a necessidade de grandes quantidades de memória externa, o que é ideal em um mercado com oferta restrita de HBM e GDDR7 em fase de escalonamento.
O acordo da Nvidia com a Groq é o maior de uma onda de aquisições focadas em inferência na indústria de semicondutores em 2025. Outras empresas como AMD, Meta e Intel também adquiriram ou investiram em startups de chips de inferência. Este padrão reflete que, apesar do mérito técnico, a economia de competir independentemente contra o ecossistema CUDA da Nvidia se tornou insustentável para muitas startups.
Enquanto as startups se consolidam, os grandes provedores de nuvem estão acelerando o desenvolvimento de seu próprio hardware de inferência. Meta, Google e AWS estão investindo fortemente em chips personalizados (MTIA, TPU, Trainium/Inferentia), demonstrando uma diversificação nos gastos com computação em data centers, com aceleradores XPU e ASICs personalizados liderando o crescimento.
A resposta da Nvidia a essa dinâmica de mercado é garantir que sua plataforma inclua silício não-GPU antes que outros o façam, e o Groq 3 LPU é o resultado dessa estratégia. O futuro do Rubin CPX permanece incerto por enquanto.